
Building and Deploying a React CV on AWS S3 with TypeScript: A Deep Dive into Headless Chromium with Puppeteer, AWS CDK, Custom Lambda Docker Runtimes and GitHub Actions - Part 1
Building and updating a beautiful CV locally with Nx Monorepos, React, Puppeteer, Headless Chromium and Docker.


In this two-part series, I'll detail how I transformed my CV into a dynamic, automated, and easily accessible digital asset. Usually when you think of getting your CV you have to go to Drive, iCloud, Dropbox or Office 365 to export the latest PDF. Additionally, while writing the CV, you not only have to wrangle with the content but also with the layout, having to deal with every indentation block, image alignment and column header.
A popular solution for the second option is to use tools such as LaTeX, a tool which is used extensively in the academic world for this exact purpose. But even so, the first issue is still present, your CV is not readily available to be handed over.
To fix the above pain points and more, as an engineer, I have done what engineers do and I went and engineered a solution to my problem and here I will outline the steps I have gone through to attain this goal. At the end of it, the CV is be versioned, linted, tested, has IaC, is CDN hosted, has CI/CD and is available for download at a click of button. The end result is available at cv.crisboarna.com.
The steps I have to follow now to update my CV are as follows:
Open .json file containing relevant section of my CV.
Perform relevant edits.
git commitgit push???
Profit!
The CI/CD pipeline takes cares of the rest and the website cv.crisboarna.com and downloadable PDF are available within 5 minutes with no further input from me. I even get an email to notify me of the latest version being published.
To obtain the end result I am using Nx monorepo with 3 apps. As there are several components that all share common symbols, such as the name of the file and all services are written in the same language, I am leveraging a powerful tool, Nx, to bootstrap and increase my development agility. Nx is similar to Lerna and Yarn workspaces in that it handles the wiring between microservices but excels beyond the competition in DevEx and bootstrapping capabilities for different use cases. There are 4 main services that coalesce to achieve the end result hosted at the above link:
@nx/react CV website
This is the actual CV, written in React
Exporter Lambda Function
This is the CloudFormation Custom Resource Lambda leveraging Docker Custom Runtime with Puppeteer driven Chromium headless browser for PDF exporting
Infrastructure code
AWS CDK NodeJS IaC(Infrastructure-as-Code) for ECR(Docker image hosting), Lambda(above exporter), S3 bucket(website distributable hosting), CloudFront CDN(web front to serve files)
GitHub Actions
Glue that binds all of the above together to lint, test, build, deploy on every pull request and merge to main.
The first two development focused points are the subject of this post and the last two DevOps focused points are the subject of the next post.
I have done this many years ago but after revisiting and updating all of the dependencies, I have run into a couple of issues that prompted a more involved refactor, the result of which is detailed here.
The Functions-as-a-Service (FaaS) offerings have been a godsend that have significantly reduced the boilerplate needed to run one-time applications in an event-driven context but sometimes you need an escape hatch to perform more advanced actions.
One such scenario is when you want to have Puppeteer orchestrate a headless Chromium browser in order to perform a PDF export of a specific web page. I have done this historically using the chrome-aws-lambda NPM package that contains a pre-built binary of Chromium leveraging default AWS provided NodeJS Lambda runtimes. Unfortunately this package has since seemingly been abandoned with no support for versions of NodeJS >=16 combined with AWS deprecating the AWS Lambda NodeJS 14 runtime, the impetus has been given to search for alternative solutions.
While there now exists @sparticuz/chromium to carry on the torch of this, with a well defined lockstep with latest Chromium Testing versions, the local testing solution suggested does not an ensure apple-to-apples comparison between the local and Lambda results which resulted in PDF’s that looked vastly different between local and Lambda.
Another issue is the above mentioned AWS deprecation of runtime versions which would manifest itself in the future for NodeJS 20.x as it has now for NodeJS 14.x at an inappropriate moment.
As such given the above, I have set to leverage the provided “escape hatch” provided by AWS and create my own custom AWS Lambda Runtime Docker image.
1. CV Website
This is a standard @nx/react bootstraped website with TypeScript and CSS modules and Webpack bundling. The content of my CV is stored within JSON files for each section and in similar vein to LaTeX, I just write the content and React deals with laying it out on the page.
There are some particularities of course as I have a 2 page A4 CV, there is special care needed at the page break so it does not cut the text midway.
The web application code can be found here. You can also run it locally or via Docker:
nx serve web
docker compose up web
2. Exporter Lambda Function
This is the Lambda that runs a headless Chromium browser using Puppeteer to load the web application and create a PDF export of it. It passes query parameters that hide the top Download and GitHub buttons for the PDF to only contain the CV itself.
The code itself is straightforward but custom enough to not be able to directly leverage a Puppeteer Docker image.
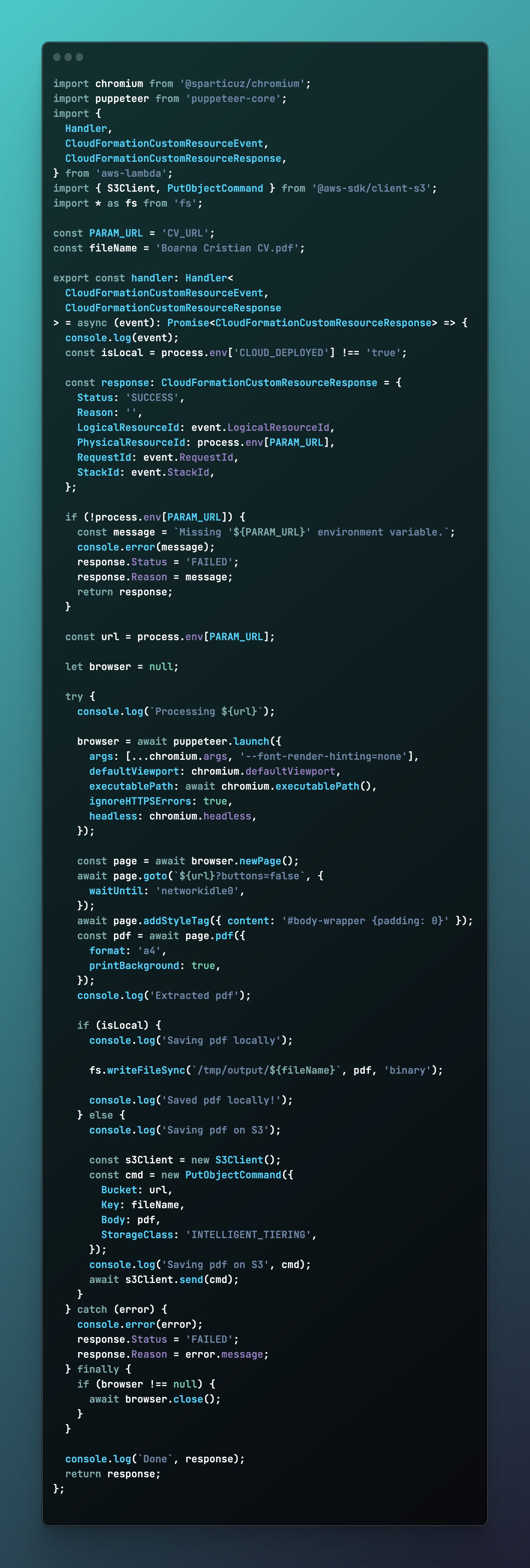
This code is built leveraging esbuild which creates similarly to webpack a bundle of the code and all third party dependnecies into a single main.js as this will be shipped in the Docker image for Lambda to run, so it does not need any splitting.
Due to the @sparticuz/chromium dependency containing binary elements, it is ignored from the bundle and installed directly within the container.

At this point the Web and Exporter services can come together locally with the help of a simple docker-compose.yaml to be able to view the end result CV PDF saved on the repository root.

Troubleshooting
A particular stumbling block that I encountered due to being on an ARM64 CPU running Chromium:
qemu-x86_64: Could not open '/lib64/ld-linux-x86-64.so.2': No such file or directory
Upon investigating I realized that only now is the Chrome team starting to roll out ARM builds for Chrome and the container having Linux ARM64 architecture would error out elusively with the above message which can easily be solved by adding
“platform: linux/amd64” to your compose file.
If you are to run it now, you will get a new error, namely:
qemu: uncaught target signal 11 (Segmentation fault) - core dumped
which is even more elusive than the last. To cut the store short, the solution to this is to enable
Docker Desktop > Features in development > Use Rosetta for x86/amd64 emulation on Apple Silicon.

These last few items only apply if you are on a M-Series Mac of course.
Now we are ready to start the web and the exporter services up and view our publishable CV website and downloadable CV PDF locally through the following 3 commands in 3 separate terminals:
nx serve:docker web
nx serve:docker exporter
curl "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{}'
The first two commands start the services and the last one invokes the Lambda runtime with an empty payload to trigger our handler which will access the CV website within the Docker network on ‘http://cv_web:4200’, as that is the configured hostname we have given the React service container and we have configured webpack for ‘0.0.0.0’ to listen on all adapters and accept connections from ‘all’.
Conclusion
I have described above how we can leverage the power of Nx monorepos to manage React & NodeJS applications and used Docker to create a custom AWS Lambda Runtime image. We also encountered and resolved issues related to running Chromium on an ARM64 CPU.
In the next part of this blog post series, we will delve into the details of setting up the Infrastructure-as-Code (IaC) using AWS CDK NodeJS and how I used GitHub Actions to automate the process of linting, testing, building, and deploying our applications. We will also discuss how I managed to host our Docker image on ECR, set up our Lambda function, and host our website distribution on an S3 bucket with CloudFront CDN.
This is a clean and beautiful approach to solving the discoverability issue of our CV while applying true and tested techniques for linting, testing, versioning and showcasing our abilities.
Please share your suggestions and opinions on my approach to solving this, I am curious to see what ideas other have and how this can be improved upon !