
Multi-Node Local Spark Cluster Alongside A DevContainer
Run Spark jobs locally with files from your local system or from your data-lake in a "batteries included" reproducible environment.


Apache Spark is a powerful distributed computing system that enables large-scale data processing. While most use cases involve deploying Spark on a cloud cluster, setting up a multi-node Spark cluster locally is invaluable for development, testing, and education. Docker Compose streamlines the process of configuring multiple Spark nodes, handling networking automatically. This eliminates the complexity of manual setups and allows you to focus on coding and testing your Spark applications. This blog post explains the steps to set up and run a multi-node Spark cluster locally within a DevContainer using Docker Compose.
When faced with any Big Data tasks such as MapReduce, Spark Streaming, MLlib (classification, regressions, clusterings, recommendations, feature extractions and others), Graph Processing (GraphX), SparkSQL and others, you usually have to jump through the hoops of accessing a remote Spark cluster to run your code that can range from installing Spark in Google Codelab to setting up an Elastic Map Reduce cluster on AWS. If you are in a sufficiently big company, you may also have internal clusters already running to connect to.
All of these require a continuous internet connection and a varying amount of setup steps. This Docker & DevContainer approach will show you a powerful alternative for rapid development cycles. In the below image you can see the overall architecture of what we will be doing here where on the developer computer we only have a thin client VSCode connecting to VSCode server within the DevContainer. This in turn communicates with the Spark Master node that deals with the inter-cluster comunication.

As we can see from the above diagram there are three ways to interface with the containers: VSCode itself, the Spark UI and the mounted volume from the local filesystem.
Note
We will not go into excruciating detail on how to setup a Spark cluster, as our purpose is to quickly get it setup and running locally as there are bigger fish to catch.
Note 2
While the target of this post is to run it all locally, we still want to keep it in line with the feature set existing on the live Spark cluster systems, as such, for the purposes of this post, we will assume the production systems use AWS EMR 7.5.0 and all our installed dependencies such as Python, Spark, Hadoop, Scala, Java JDK will try to adhere to the versions specified in the AWS EMR release notes.
Advantages
Requires no more internet connection
You can go on a plane with this setup and keep progressing on big data tasks.
If you are travelling in low signal areas.
Significantly reduce development start-run-complete loops for your tasks as all data would be co-located on same SSD with your cluster.
Canary release
You can use this setup to quickly test your pipelines work with a new major/minor release of your Spark cluster and dependnecies. It is a lot easier and faster to bump the version in the Dockerfile and run your pipelines than it is to try to deploy a new cluster on a vendor’s platform, configure it and retarget your existing DEV/QA/Production environments.
Ease of setup
Using Docker Compose automates the configuration of multiple nodes. It simplifies the networking and avoids manual setup headaches.
Consistency
DevContainers ensure that the development environment remains consistent across different machines, reducing the classic "works on my machine" problem.
Cost-effectiveness
A local cluster eliminates the need for cloud resources, making it ideal for development and education purposes.
Flexibility
You can customize Spark’s configurations to mimic production environments or test new features without affecting actual clusters.
Disadvantages
Resource contraints
Running a multi-node cluster locally is resource-intensive and may not accurately represent the performance of real distributed environments. But for ironing out the logic this should not matter as much.
If leveraging only a local dataset, you are limited in the amount of data that can be run through your job, but for rapid development and experimentation, you would be leveraging a subset of your data regardless, so this should not be as big of an issue.
Implementation
The crux of the magic for this can be found in the docker-compose.yaml file with some shell scripts for setup of the various containers.
Prerequisites
Docker and Docker Compose installed.
Visual Studio Code with the DevContainers extension.
Basic familiarity with Docker and Spark.
Step 1: devcontainer.json
The main definition file for any DevContainer in VSCode is the .devcontainer/devcontainer.json file which specifies all of the configuration aspects for your setup.
We will use a more advanced, “escape hatch” approach leveraging Docker Compose for this task, as such we use the “dockerComposeFile” and the “service” properties in particular to provide more advanced container configuration options.

The rest of the “customizations” category is aimed at configuring VSCode to a “batteries included” approach for Python Spark development. Adding Scala/Java plugins and configurations would be needed to get it running for both languages.
Step 2: Docker Compose YAML
As mentioned above, we are delegating to Docker Compose the exact DevContainer configuration, which allows us to setup not only the container in which VSCode will configure it’s remote server but also auxiliary containers to augment our development experience, such as a 3-node Spark cluster with a master and two slaves.

Step 3: Dockerfile
The third element of the trio of core files for this exercise is the multi-stage Dockerfile which contains all of the common and shared setup logic for the development and Spark containers.

Step 4: PySpark test harness
Now we need some simple code that can be submitted as a Spark job to verify that all the wiring is done properly, cluster communication is working and that the execution completes successfully.

Step 5: VSCode Task run configuration
In order to easily run the code without having to copy paste from anywhere or remember “Yet-Another-Command”, we can create task run configurations to be invoked with “SHIFT + ⌘ + P” > “Tasks: Run Task”

Step 6: Execute PySpark job
We can now run the above task and receive the following successful output:

It has read the public transport CSV file downloaded from here and placed in “/workspace/data/B63.csv” and outputted the top values from the DataFrame in the console, as expected.
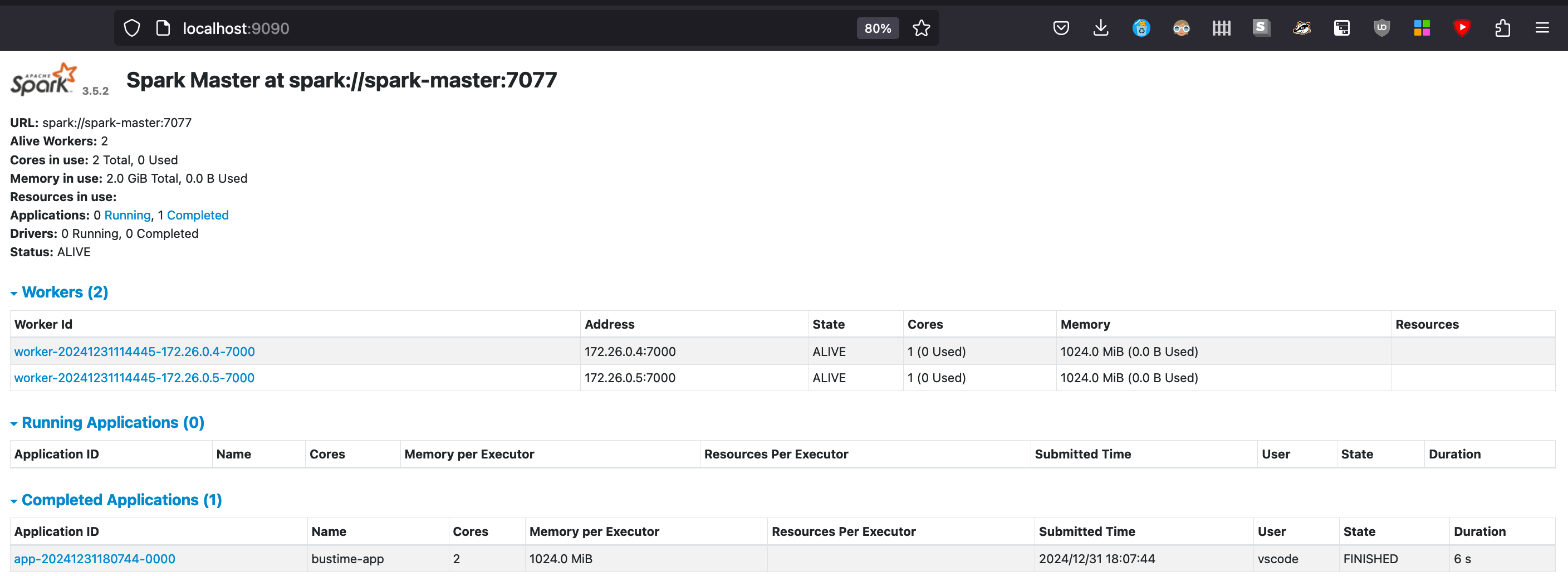
We can also go to http://localhost:9090 to view the SparkUI and see the app “bustime-app” executed successfully.
Step 7: Use Jupyter Notebook (Optional)
As any data scientist will know, running an entire end-to-end pipeline may take a very long time and as our purpose here is to have as fast as possible development & feedback cycles, we can create a .ipynb file, connect it to the installed Python kernel and run individual jobs from there.

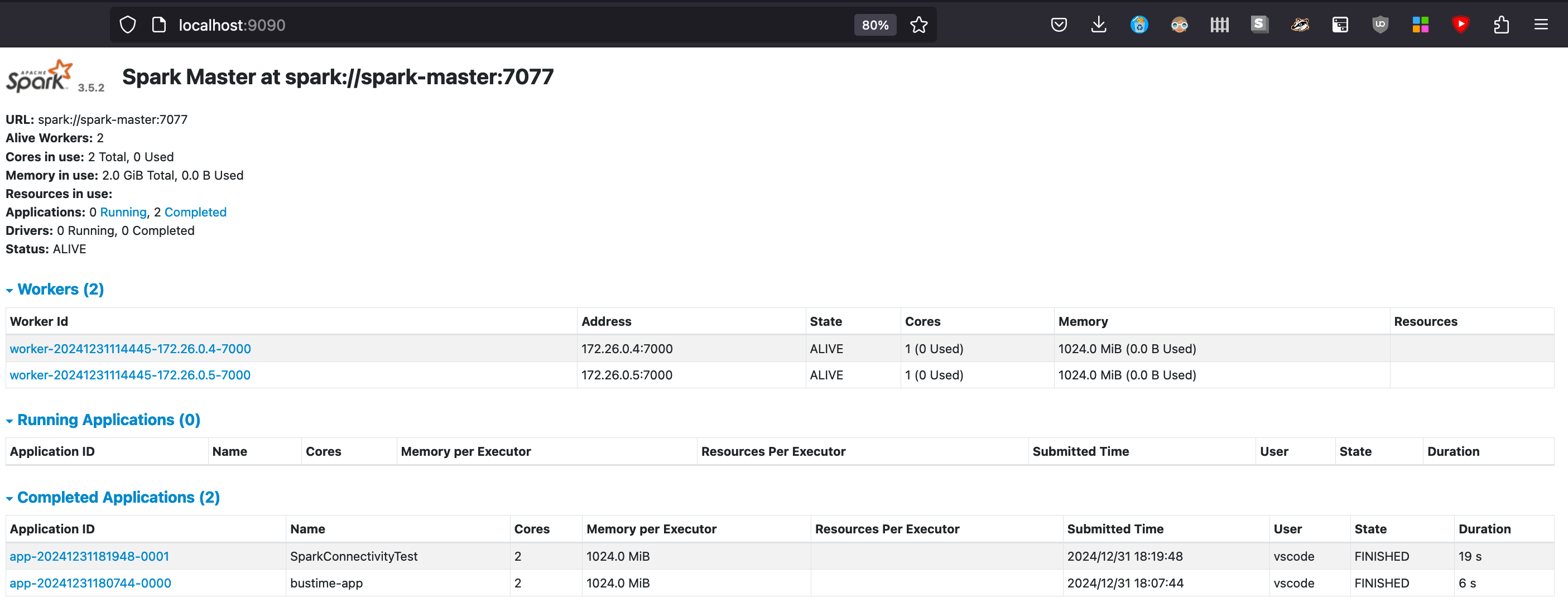
We can also confirm using the Spark UI that the job has been submitted and executed properly on the cluster by verifying the existence of the “SparkConnectivityTest” job in the list.
Conclusion
Setting up a local multi-node Spark cluster using Docker Compose and DevContainers provides a practical environment for development and testing. While it’s resource-limited compared to production, it’s an excellent tool for learning and debugging. By following the steps in this guide, you can create a Spark cluster that’s easy to manage, reproducible, and flexible.
Experiment with different configurations and integrate additional tools to enrich your development experience. The combination of Docker Compose and DevContainers ensures your environment is consistent, cost-effective, and aligned with best practices. While we skipped over some of the tertiary files part of this setup, you can find the entire repository for this post here.